详解实用拜占庭协议Pbft(一)
PBFT算法和Raft算法解决的核心问题都是在分布式环境下如何保持集群状态的一致性,简而言之就是一组服务,给定一组操作,最后得到一致的结果。
PBFT算法假设的环境又比Raft算法更加的’恶劣‘,Raft算法只支持容错故障节点,而PBFT算法除了需要支持容错故障节点之外,还需要容忍作恶节点。
作恶节点节点是指可能对接收到的消息作出截然相反的回复,甚至伪造消息。
PBFT算法中节点只有两种角色,主节点(primary)和副本(replica),两种角色之间可以相互转换。两者之间的转换又引入了视图(view)的概念,视图在PBFT算法中起到逻辑时钟的作用。
为了更多的容错性,PBFT算法最大的容错节点数量( n - 1 ) / 3,也就是是说4个节点的集群最多只能容忍一个节点作恶或者故障。而Raft算法的最大容错节点是( n - 1) / 2,5个节点的集群可以容忍2个节点故障。
为什么PBFT算法只能容忍(n-1)/3个作恶节点?
节点总数是n,其中作恶节点有f,那么剩下的正确节点为n - f,意味着只要收到n - f个消息就能做出决定,但是这n - f个消息有可能由f个是由作恶节点冒充的,那么正确的消息就是n - f - f个,为了多数一致,正确消息必须占多数,也就是n - f - f > f但是节点必须是整数个,所以n最少是3f+1个。
或者可以这样理解,假定f个节点是故障节点,f个节点是作恶,那么达成一致需要的正确节点最少就是f+1个,当然这是最坏的情况,如果故障节点集合和拜占庭节点集合有重复,可以不需要f+1个正确节点,但是为了保证最坏的情况算法还能正常运行,所以必须保证正确节点数量是f+1个。
算法流程
在算法开始阶段,主节点由 p = v mod n计算得出,随着v的增长可以看到p不断变化,论文里目前还是轮流坐庄的方法,这里是一个优化点。
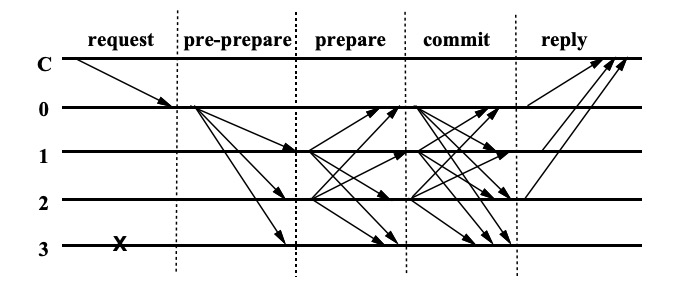
首先客户端发送消息m给主节点p,主节点就开始了PBFT三阶段协议,三个阶段分别是预准备(pre-prepare),准备(prepare),提交(commit)。
其中pre-prepare和prepare阶段最重要的任务是保证,同一个主节点发出的请求在同一个视图(view)中的顺序是一致的,prepare和commit阶段最重要的任务是保证请求在不同视图之间的顺序是一致的。
- 主节点收到客户端发送来的消息后,构造
pre-prepare消息结构体< <PRE-PREPARE, v, n, d>, m >广播到集群中的其它节点。PRE-PREPARE标识当前消息所处的协议阶段。v标识当前视图编号。n为主节点广播消息的一个唯一递增序号。d为m的消息摘要。m为客户端发来的消息。
副本(backup)收到主节点请求后,会对消息进行检查,检查通过后会将消息存储在本节点,并且变更自身状态到PREPARE状态。状态变更完成后,节点广播消息< <PREPARA, v, n, d, i> >,其中i是本节点的编号。对消息的有效性有如下检查:- 检查收到的消息体中摘要
d,是否和自己对m生成的摘要一致,确保消息的完整性。 - 检查
v是否和当前视图v一致。 - 检查序号
n是否在水线h和H之间,避免快速消耗可用序号。 - 检查之前是否接收过相同序号
n和v,但是不同摘要d的消息。
- 检查收到的消息体中摘要
副本收到2f+1(包括自己)个一致的PREPARE消息后,会进入COMMIT阶段,并且广播消息< COMMIT, v, n, D(m), i >给集群中的其它节点。在收到PREPARE消息后,副本同样也会对消息进行有效性检查,检查的内容是上文1, 2, 3。副本收到2f+1(包括自己)个一致的COMMIT个消息后执行m中包含的操作,其中,如果有多个m则按照序号n从小到大执行,执行完毕后发送执行成功的消息给客户端。
下面就是算法的流程图: