
详解实用拜占庭协议Pbft(三)
主动恢复
集群在运行过程中,可能出现网络抖动、磁盘故障等原因,会导致部分节点的执行速度落后大多数节点,而传统的PBFT拜占庭共识算法并没有实现主动恢复的功能,因此需要添加主动恢复的功能才能参与后续的共识流程,主动恢复会索取网络中其他节点的视图,最新的区块高度等信息,更新自身的状态,最终与网络中其他节点的数据保持一致。
在Raft中采用的方式是主节点记录每个跟随者提交的日志编号,发送心跳包时携带额外信息的方式来保持同步,在Pbft中采用了视图协商(NegotiateView)的机制来保持同步。
一个节点落后太多,这个时候它收到主节点发来的消息时,对消息水线(water mark)的检查会失败,这个时候计时器超时,发送view-change的消息,但是由于只有自己发起view-change达不到2f+1个节点的数量,本来正常运行的节点就退化为一个拜占庭节点,尽管是非主观的原因,为了尽可能保证集群的稳定性,所以加入了视图协商(NegotiateView)机制。
当一个节点多次view-change失败就触发NegotiateView同步集群数据,流程如下;

- 新增节点
Replica 4发起NegotiateView消息给其他节点; - 其余节点收到消息以后,返回自己的视图信息,节点ID,节点总数N;
Replica 4收到2f+1个相同的消息后,如果quorum个视图编号和自己不同,则同步view和N;Replica 4同步完视图后,发送RevoeryToCheckpoint的消息,其中包含自身的checkpoint信息;- 其余节点收到
RevoeryToCheckpoint后将自身最新的检查点信息返回给Replica 4; Replica 4收到quorum个消息后,更新自己的检查点到最新,更新完成以后向正常节点索要pset、qset和cset的信息(即PBFT算法中pre-prepare阶段、prepare阶段和commit阶段的数据)同步至全网最新状态;
增删节点
Replica 5新节点加入的流程如下图所示;
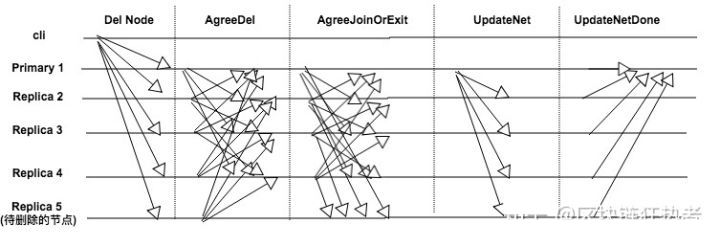
- 新节点启动以后,向网络中其他节点建立连接并且发送
AddNode消息; - 当集群中的节点收到
AddNode消息后,会广播AgreeAdd的消息; - 当一个节点收到
2f+1个AgreeAdd的消息后,会发送AgreeAdd的消息给Replica 5 Replica 5会从收到的消息中,挑选一个节点同步数据,具体的过程在主动恢复中有说明,同步完成以后发送JoinNet- 当集群中其他节点收到
JoinNet之后重新计算视图view,节点总数N,同时将PQC信息封装到AgreeJoinOrExit中广播 - 当收到
2f+1个有效的AgreeJoinOrExit后,新的主节点广播UpdateNet消息完成新增节点流程
删除节点的流程和新增节点的过程类似:

QA
Q:为什么PBFT算法需要三个阶段?
A:假如简化为两个阶段pre-prepare和prepare,当一个节点A收到2f+1个相同的prepare后执行请求,一部分节点B发生view-change,在view-change的过程中是拒收prepare消息的,所以这一部分节点的状态机会少执行一个请求,当view-change切换成功后重放prepare消息,在重放的过程中,节点A也完成了view-change,这个时候A就会面临重放的prepare已经执行过了,是否需要再次执行?会导致状态机出现二义性。
Q:view-change阶段集群会不可用么?
A:view-change阶段集群会出现短暂的不可用,一般在实践的时候都会实现一个缓冲区来减少影响,实现参考 以太坊TXpool分析。
Q:Pbft算法的时间复杂度?
A:Pbft算法的时间复杂度O(n^2),在prepare和commit阶段会将消息广播两次,一般而言,Pbft集群中的节点都不会超过100。