
Merkle Patricia Tree (MPT) 树详解之数据结构(一)
在之前的EVM系列的文章中,其实一直有一个问题没有解决,那就是Storage持久化的数据最终是以什么样的形式,保存在哪里?数以万计的合约有数以万计的storage变量,这些变量如何快速的读写?
字典树(Trie)
Trie又称前缀树或字典树,是一种有序多叉树。下图是一颗典型的前缀树;
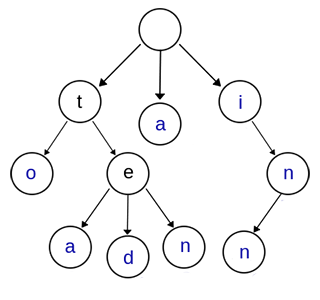
图中前缀树存储了一些字符串,蓝色的是关键字,存储的字符串由关键字组成。存储了”a”, “to”, “tea”, “ted”, “ten”, “i”, “in”, “inn”。
前缀树有这些特点;
- 根节点不包含字符,其他节点各包含一个字符;
- 关键路径节点的字符连接起来为该节点所存储的数据;
关键路径就是每个节点有一个标志位,用来标记这个节点是否作为构成数据的一部分,上图中的,t, e 节点就不是关键路径。
Trie的核心思想就是用空间换时间,利用公共前缀缩小要比较的范围来达到快速查找的目的。
优点
- 插入和查询的效率都很高,都是O(m),m是插入或查询字符串的长度。
- 可以对数据按照字典序排序。
缺点
- 空间消耗的比较大。
典型场景
- 但词频次统计。
- 字符串匹配。
- 字符串字典序排序。
- 前缀匹配,比如一些搜索框的自动提示。
压缩字典树
压缩字典树在字典树的基础之上做了一些优化,具体可以看下图;

图中黑色的是关键路径,存储了字符串”abc”和”d”,但是明显可以看到压缩后的前缀树占用了更小的空间。
默克尔树(Merkle tree)
默克尔树首先计算叶子节点的hash值,然后将相邻两个节点的哈希进行合并,合并完成后计算这个字符串的哈希值,直到根节点为止,如果是单个节点,可以复制单节点的哈希,然后合并哈希再重复上面的过程。

优点
可以高效安全的验证数据结构的内容。
典型场景
p2p网络分块下载文件的时候,快速校验下载到的数据是否完整,是否遭到破坏。
默克尔帕特里夏树(Merkle Patricia Tree)
MPT树结合了字典树和默克尔树的优点,在压缩字典树中根节点是空的,而MPT树可以在根节点保存整棵树的哈希校验和,而校验和的生成则是采用了和默克尔树生成一致的方式。
以太坊采用MPT树来保存,交易,交易的收据以及世界状态,为了压缩整体的树高,降低操作的复杂度,以太坊又对MPT树进行了一些优化。将树节点分成了四种;
- 空节点(hashNode)
- 叶子节点(valueNode)
- 分支节点(fullNode)
- 扩展节点(shortNode)
通过以太坊黄皮书中很经典的一张图,来了解不同节点的具体结构和作用

可以看到有四个状态要存储在世界状态的MPT树中,需要存入的值是键值对的形式。自顶向下,我们首先看到的keccak256生成的根哈希,参考默克尔树的Top Hash,其次看到的是绿色的扩展节点Extension Node,其中共同前缀shared nibble是a7,采用了压缩前缀树的方式进行了合并,接着看到蓝色的分支节点Branch Node,其中有表示十六进制的字符和一个value,最后的value是fullnode的数据部分,最后看到紫色的叶子节点leadfNode用来存储具体的数据,它也对路径进行了压缩。
在智能合约执行以后,有一部分数据是需要持久化,参考「EVM深度分析之数据存储(一)」中的Storage中的类型,而一条链上有非常多的合约,每个合约又有很多的数据需要持久化,这个时候就需要用到MPT树。
在「EVM深度分析之数据存储」中可以看到需要持久化的数据都是以键值对的形式存在的,而键是由keccak256这个函数计算得到,用十六进制表示后刚好对应 MPT 树中分支节点的0-f的16个分支。
为了避免不同合约有相同的字段,合约又通过地址来进行管理,具体参考「以太坊账户组织形式」,本质上也是采用MPT树管理合约,合约又采用MPT树管理自身状态。
最终的数据还是以键值对的形式存储在LevelDB中的,MPT树相当于提供了一个缓存,帮助我们快速找到需要的数据,至于最终落盘的数据后面在讲~